Datus 教程:上下文数据工程完整演练¶
理解和实践上下文数据工程的分步指南
本教程将带您完整体验 Datus-agent 的工作流程:
- 构建知识库(元数据 / 指标 / 参考 SQL)
- 生成两个带有工具和上下文的 subagent
- 使用 Datus-CLI 探索数据上下文
- 对它们进行基准测试以比较准确性和性能
- 运行多轮评估以展示上下文数据工程的价值
1. 前置条件:初始化 Datus Agent¶
运行教程之前,请先初始化您的 Datus agent:
由于本教程涉及指标生成,还需要安装语义层适配器:
详细的设置说明请参见快速开始指南。
2. 运行教程¶
启动引导式教程:
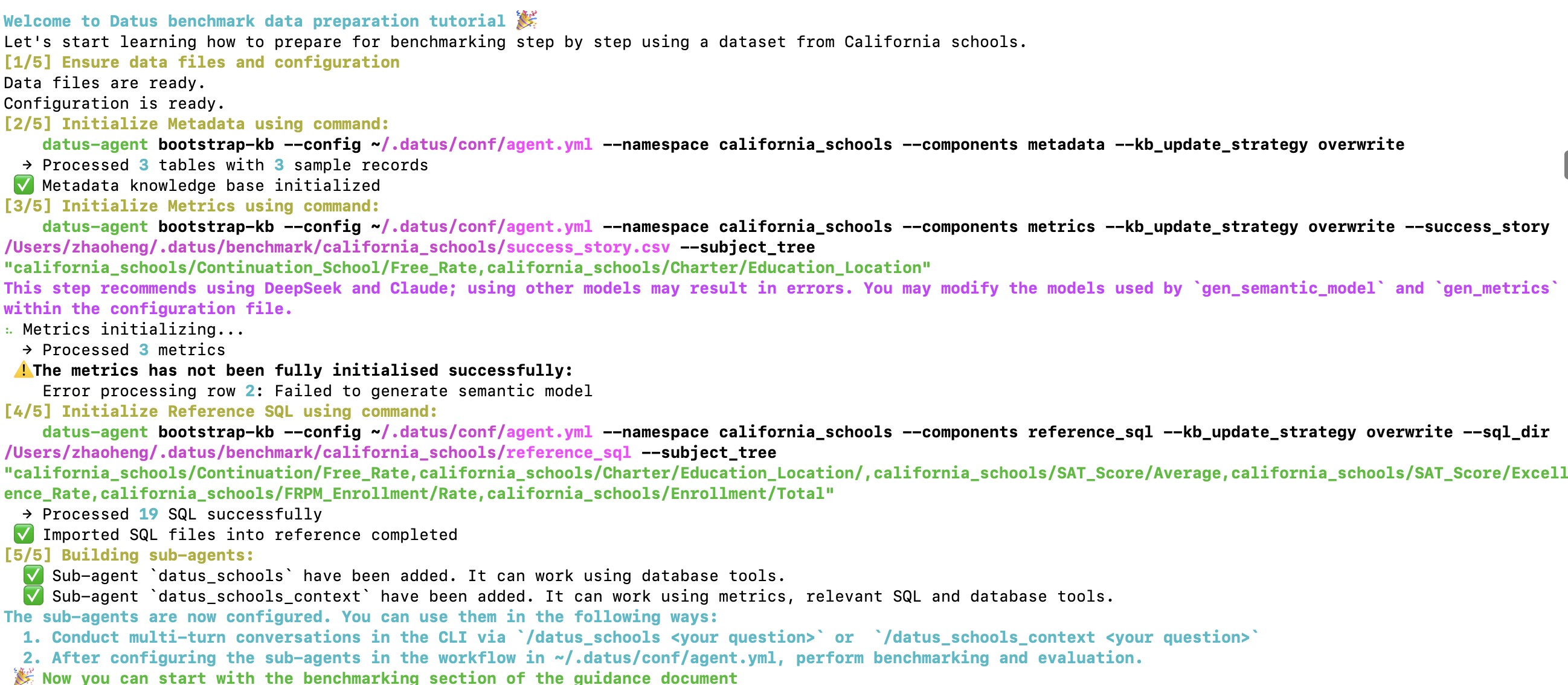
您将看到一个结构化的 5 步工作流程。通过多轮 agent 调用,这个过程大约需要 10 分钟完成初始化。您可以在等待过程中观察 Datus 的执行过程,以了解其工作原理。
步骤 [⅕] 验证数据和配置¶
Welcome to Datus tutorial 🎉
Let's start learning how to prepare for benchmarking step by step using a dataset from California schools.
[1/5] Ensure data files and configuration
Data files are ready.
Configuration is ready.
教程会检查:
- 复制并验证示例数据集(california_schools)
- 验证 success_story.csv 文件存在
- 确认 reference_sql/ 目录存在
- 使用配置更新 agent.yml
步骤 [⅖] 初始化元数据¶
[2/5] Initialize Metadata using command:
datus-agent bootstrap-kb \
--config ~/.datus/conf/agent.yml \
--namespace california_schools \
--components metadata \
--kb_update_strategy overwrite
示例输出:
Datus 将连接到示例数据集,提取表结构和数据样本,然后将它们存储到带有向量索引的知识库中。了解更多关于元数据管理。
步骤 [⅗] 初始化指标¶
指标生成严重依赖于语义建模,因此推荐使用强大的 agentic 模型(推荐模型:DeepSeek / Claude)。更多详情请参见指标文档。
[3/5] Initialize Metrics using command:
datus-agent bootstrap-kb \
--config ~/.datus/conf/agent.yml \
--namespace california_schools \
--components metrics \
--kb_update_strategy overwrite \
--success_story ~/.datus/benchmark/california_schools/success_story.csv \
--subject_tree "california_schools/Continuation_School/Free_Rate,california_schools/Charter/Education_Location"
理解参数:
--success_story:包含问题和 SQL 示例对的 CSV 文件。LLM 将分析这些示例以提取和生成业务指标。--subject_tree:预定义的语义层分类结构(例如california_schools/Continuation_School/Free_Rate)。LLM 将把生成的指标组织到这个主题树的适当叶子节点中。
示例输出:
⠦ Metrics initializing...
→ Processed 3 metrics
⚠️ The metrics has not been fully initialised successfully:
Error processing row 2: Failed to generate semantic model
注意 如果指标初始化失败,请在 agent.yml 中调整
gen_semantic_model和gen_metrics的模型配置。如果您在开始时没有足够的成功案例样本,可以安全地忽略这些错误。
步骤 [⅘] 初始化参考 SQL¶
有关参考 SQL 的更多信息,请参见参考 SQL 文档。
datus-agent bootstrap-kb \
--config ~/.datus/conf/agent.yml \
--namespace california_schools \
--components reference_sql \
--kb_update_strategy overwrite \
--sql_dir ~/.datus/benchmark/california_schools/reference_sql \
--subject_tree "california_schools/Continuation/Free_Rate,california_schools/Charter/Education_Location/,california_schools/SAT_Score/Average,california_schools/SAT_Score/Excellence_Rate,california_schools/FRPM_Enrollment/Rate,california_schools/Enrollment/Total"
理解参数:
--sql_dir:包含参考 SQL 文件的目录。Datus 将解析、分析和分段这些 SQL 文件以构建可重用的 SQL 摘要。--subject_tree:手动设计的分类结构。LLM 将把 SQL 摘要分类并组织到适当的主题树节点中。建议手动设计此分类结构以获得更好的组织。
输出:
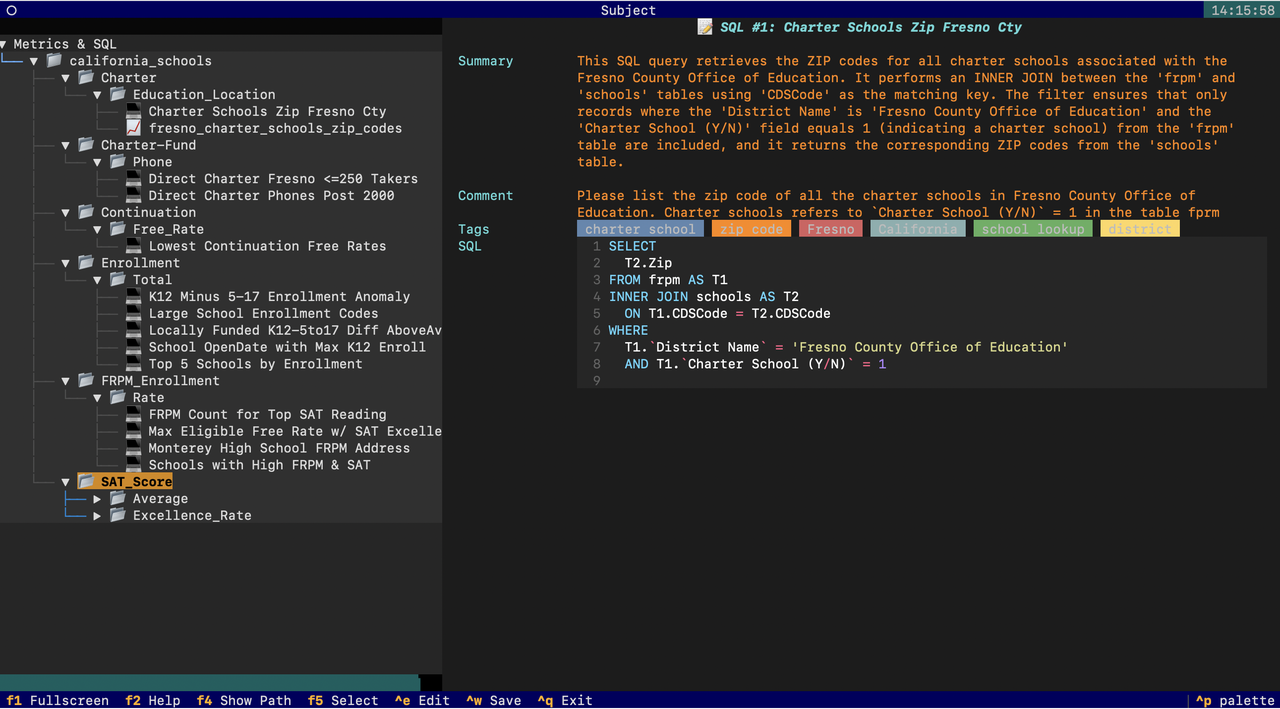
您可以使用 Datus-CLI 探索 Datus 生成的指标和参考 SQL:
步骤 [5/5] 构建 Subagent¶
教程会自动生成两个 subagent:
[5/5] Building sub-agents:
✅ Sub-agent `datus_schools` have been added. It can work using database tools.
✅ Sub-agent `datus_schools_context` have been added. It can work using metrics, relevant SQL and database tools.
查看 agent.yml 配置文件以了解 subagent 的定义:
agentic_nodes:
datus_schools:
system_prompt: datus_schools
prompt_version: '1.0'
prompt_language: en
agent_description: ''
tools: db_tools, date_parsing_tools
mcp: ''
rules: []
datus_schools_context:
system_prompt: datus_schools_context
prompt_version: '1.0'
prompt_language: en
agent_description: ''
tools: context_search_tools, db_tools, date_parsing_tools
mcp: ''
rules: []
workflow:
datus_schools:
- datus_schools
- execute_sql
- output
datus_schools_context:
- datus_schools_context
- execute_sql
- output
理解配置:
agentic_nodes:定义具有不同能力的两个 subagent
datus_schools:基线 agent,仅有db_tools和date_parsing_toolsdatus_schools_context:上下文丰富的 agent,具有额外的context_search_tools,可以访问知识库中的指标和参考 SQL
workflow:定义每个 agent 的执行流程。这些工作流旨在将结果输出到文件,便于评估和比较 agent 性能。
- 步骤 1:Subagent 分析问题并生成 SQL
- 步骤 2:
execute_sql节点执行生成的 SQL 以产生最终结果 - 步骤 3:
output节点格式化并将结果写入本地磁盘
关键区别在于 datus_schools_context 可以访问 context_search_tools,使其能够利用您在之前步骤中构建的指标和参考 SQL。
您现在可以:
或使用 Datus-Chat 中的聊天机器人。
3. 比较 Subagent 性能¶
这是教程的关键部分:比较**无上下文** agent 与**上下文丰富** agent。
3.1 评估 datus_schools(基线)¶
datus-agent benchmark --namespace california_schools --benchmark california_schools --workflow datus_schools
保存结果:
datus-agent eval --namespace california_schools --benchmark california_schools --output_file schools1.txt

3.2 评估 datus_schools_context(完整上下文)¶
datus-agent benchmark --namespace california_schools --benchmark california_schools --workflow datus_schools_context
保存结果:
datus-agent eval --namespace california_schools --benchmark california_schools --output_file schools2.txt
通过比较 schools1.txt 和 schools2.txt,您可以明确地看到上下文丰富的 agent 如何提高 SQL 准确性、减少错误并生成更符合语义的查询,相比基线 agent 有显著改进。
4. 多轮基准测试¶
这是上下文数据工程最强大的演示:
python -m datus.multi_round_benchmark \
--config ~/.datus/conf/agent.yml \
--namespace california_schools \
--benchmark california_schools \
--workflow datus_schools_context \
--max_round 4 \
--group_name context_tools
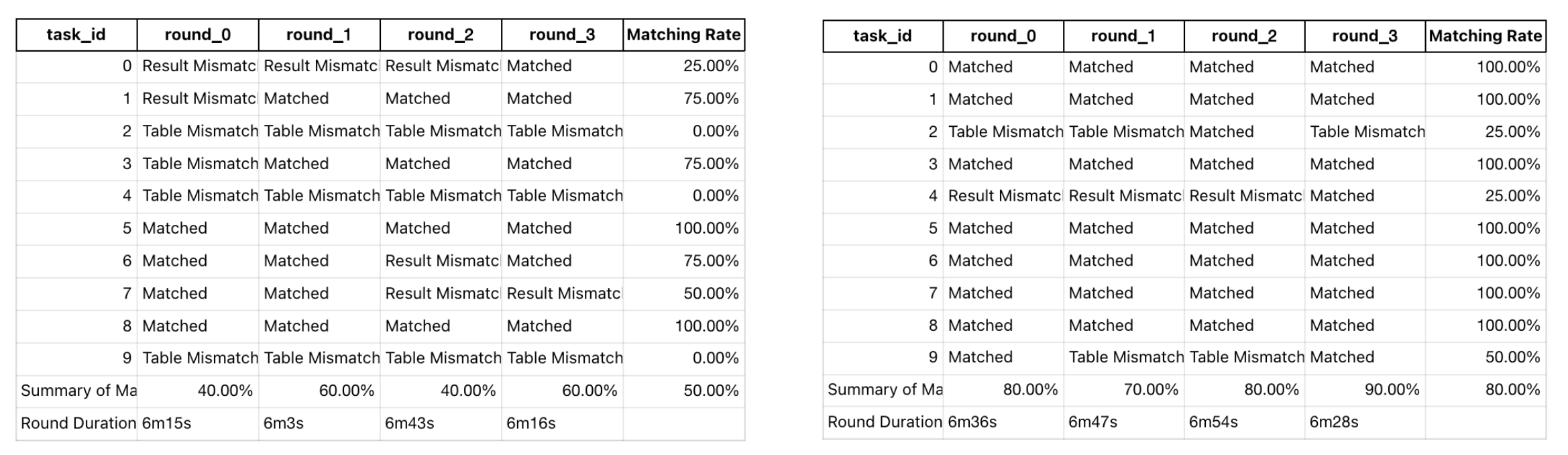
左图显示无数据上下文工具(datus_schools)的基准测试结果,右图显示有数据上下文工具(datus_schools_context)的基准测试结果。注意当上下文可用时准确性的显著提升。
5. 总结¶
完成本教程后,您已经:
| 组件 | 您的成就 |
|---|---|
| 元数据引导 | 加载了架构、列描述和物理结构 |
| 指标引导 | 创建了语义模型和业务指标 |
| 参考 SQL 导入 | 捕获了真实的 SQL 模式和连接 |
| Subagent 创建 | 构建了领域范围的、上下文丰富的 agent |
| 基准测试 | 测量了 SQL 正确性和 LLM 可靠性 |
| 多轮评估 | 观察了上下文如何随时间提高准确性 |
您现在拥有: